Classical K-Nearest Neighbor Algorithm in Python
The K-nearest neighbor algorithm is a supervised learning algorithm used to classify data-points based on multiple features. It can handle both qualitative and quantitative data. The core logic of the algorithm is to compare the new data point to all the existing data-points in it's database and assign it to the group which it most resembles. Apart from the dataset, the algorithm also requires the user to define a parameter 'K'. To understand why this parameter is needed, one must have at-least a rough idea of the inner workings of the algorithm.
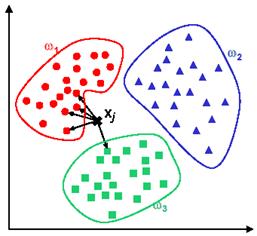 |
| Image taken from the web |
What the algorithm basically does is it sorts every data-point in it's database according to decreasing degree of similarity to the new data-point. Now, this sorted list may have points from every class of the data-set; so, to give a "best guess" answer of the classification problem, it takes a vote. For this vote it chooses the top K items in the list and assigns the new data-point to the class which has a majority in this population. A good value of K usually depends on the size of the population and for large data-sets, it is enough to choose a K at around 10% of the total population.
It's application may range anywhere from segregating customers of a supermarket into different categories to writing software for solving captcha autonomously.
 |
| Example of a captcha (taken from the web) |
The python code for this algorithm has been given below (I use the Spyder IDE).You can also download it from my Github page. Any contribution and improvement to the code is duly welcome. The code is plug and play.
Note: Apart from the standard python packages, you will also need numpy and pandas to use this code.
The code...
############################################################################
import numpy as np
import operator
import pandas as pd
if __name__ == "__main__":
print ("Welcome to K-nearest neighbor supervised learning classifier.\n\
All you will need to do is give your dataset and your unclassified feature set and this program will classify it for you\n\
Please keep in mind that the data must be in a csv file or else you will have to modify the source code\n\
\n\
so lets begin...")
da=[]
mother_file=raw_input("please mention the name of your mother file\n")
da = pd.read_csv(mother_file)
d=np.mat(da)
dataset=d[:,0:-1]
labels=d[:,-1]
inx=raw_input("please enter your input parameters in the form of a list ")
x=np.mat(inx)
if x.shape[1]!=dataset.shape[1]:
print ("invalid input\n please run the program again")
kay=raw_input("how many nearest neighbours(k) would you like to count the majority from\n")
k=int(kay)
siz=dataset.shape[0]
bl=np.zeros([dataset.shape[0],dataset.shape[1]])
for i in range(len(bl)):
bl[i,:]=x
difmat=bl-dataset
sqdifmat=np.square(difmat.astype(float))
root=np.sqrt(sqdifmat)
distances = root.sum(axis=1)
sortedDistIndicies = np.argsort(distances,axis=0)
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
print sortedClassCount[0][0]
##############################################################
 The code can handle an arbitrary number of features and does a better job than the Matlab code seen before on this blog.
The code can handle an arbitrary number of features and does a better job than the Matlab code seen before on this blog.
Remember, the input that you give to the algorithm must be in the form of a list.
import operator
import pandas as pd
if __name__ == "__main__":
print ("Welcome to K-nearest neighbor supervised learning classifier.\n\
All you will need to do is give your dataset and your unclassified feature set and this program will classify it for you\n\
Please keep in mind that the data must be in a csv file or else you will have to modify the source code\n\
\n\
so lets begin...")
da=[]
mother_file=raw_input("please mention the name of your mother file\n")
da = pd.read_csv(mother_file)
d=np.mat(da)
dataset=d[:,0:-1]
labels=d[:,-1]
inx=raw_input("please enter your input parameters in the form of a list ")
x=np.mat(inx)
if x.shape[1]!=dataset.shape[1]:
print ("invalid input\n please run the program again")
kay=raw_input("how many nearest neighbours(k) would you like to count the majority from\n")
k=int(kay)
siz=dataset.shape[0]
bl=np.zeros([dataset.shape[0],dataset.shape[1]])
for i in range(len(bl)):
bl[i,:]=x
difmat=bl-dataset
sqdifmat=np.square(difmat.astype(float))
root=np.sqrt(sqdifmat)
distances = root.sum(axis=1)
sortedDistIndicies = np.argsort(distances,axis=0)
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
print sortedClassCount[0][0]
##############################################################
How to format the data...
For the code to work without you needing to poke around the script itself, your data needs to be stored in a .csv file. The given code can handle alphanumeric designation of the class but its feature description needs to be strictly numeric.
Something like so...
Remember, the input that you give to the algorithm must be in the form of a list.
No comments:
Post a Comment